
【今日资讯】轻量化安全工具 “死了么” App 火爆全网 →
1. 轻量化安全工具 “死了么” App 火爆全网 ,称会认真研究改名事宜
日前,一款名为 “死了么” 的 App 在网络走红,并且位居苹果 App Store 付费榜 第一名(价格为 8 元)。
据介绍,该应用是为独居人群打造的轻量化安全工具,用户需要设置紧急联系人并签到,若连续多日没在应用内签到,系统将于次日自动发送邮件告知紧急联系人。1 月 11 日,“死了么” 团队针对热度及相关话题进行了回应。针对 “死了么” 这一争议名字,团队表示 “感谢大家对新名称的积极建议,我们都会认真研究和考虑”。
软件付费方面,“死了么” 透露,为了让项目能够健康、持续地发展,并覆盖日益增长的短信、服务器等成本,因此遂基于成本推出 8 元付费方案。“希望能够得到大家的理解与支持。”“死了么” 团队在文中提到,感谢所有网友的热情支持,以及媒体的关注与报道。
据悉,该团队由三名 95 后共同创立并独立运营。团队还表示,未来其将把主要精力投入到产品打磨中,例如丰富短信提醒功能、考虑增加留言功能,并探索推出更适老化的新产品。(OSCHINA)

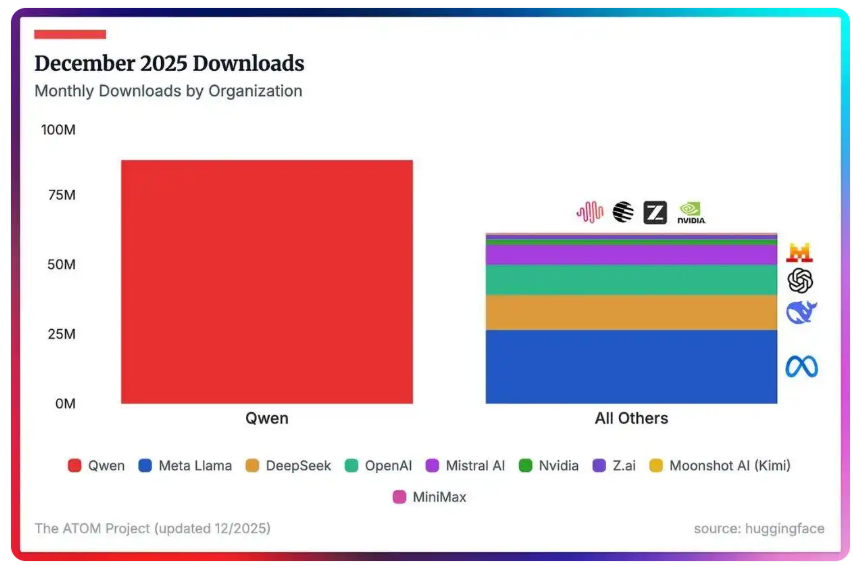
2. 阿里千问模型 12 月下载量超 2 到 9 名总和
Hugging Face 最新数据显示,阿里千问大模型迎来爆发式增长,仅在 2025 年 12 月,千问模型下载量便超过了 2 到 9 名总和,包括 Meta、DeepSeek、OpenAI、Mistral、英伟达、智谱、月之暗面、MiniMax。
数据显示,阿里千问自 2025 年下半年下载量超越 Meta 以来,累计下载量突破 7 亿,增势在全球前十开源模型中最为迅猛,逐渐拉开与其他开源模型的差距,是目前全球开发者采用率最高的开源模型。
全球开源模型生态进入 “历史性拐点”。进入 2025 年,随着阿里千问、DeepSeek 等国产 AI 的持续迭代优化,突破了以 Llama、Mistral 为代表的欧美开源模型主导的开源生态,中国模型成为全球 AI 开发者的首要选择。截至目前,阿里千问总共开源近 400 个模型,衍生模型数量突破 18 万,稳居全球第一开源大模型。数据还显示,自去年下半年以来,阿里千问模型全球下载量呈指数级上升趋势,增速在五大主流开源模型厂商中位居首位,且截至当前仍保持强劲的上升势头。
美国 AI 专家内森・兰伯特通过对数据的深入分析指出,千问系列的爆发式增长,很大程度上得益于千问 3 系列在轻量级模型上的前瞻性布局。(OSCHINA)
3. 国家网信办:2025 年新增 446 款生成式人工智能服务完成备案
1 月 9 日消息,国家互联网信息办公室今日发布“关于发布 2025 年生成式人工智能服务已备案信息的公告”。
公告称,促进生成式人工智能服务创新发展和规范应用,网信部门会同有关部门按照《生成式人工智能服务管理暂行办法》要求,持续开展生成式人工智能服务备案工作。
2025 年全年新增 446 款生成式人工智能服务在国家网信办完成备案,对于通过 API 接口或其他方式直接调用已备案模型能力的生成式人工智能应用或功能,由地方网信办开展登记,新增 330 款完成登记。
截至 2025 年 12 月 31 日,累计有 748 款生成式人工智能服务完成备案,435 款生成式人工智能应用或功能完成登记。(IT之家)

4. DeepSeek 开源大模型记忆模块:梁文锋署名新论文,下一代稀疏模型提前剧透
DeepSeek团队在大语言模型领域公布了一项创新成果——条件记忆模块Engram。该模块旨在为Transformer架构补充知识查找机制,通过回归传统的N-gram方法,以极高的效率(O(1)时间复杂度)检索固定实体名称和短语等静态知识,从而避免模型在识别静态概念时消耗过多计算资源。Engram模块通过哈希查找和上下文感知的门控机制,解决了传统N-gram模型的存储爆炸和多义性问题,并与Transformer架构有机结合。
实验表明,在27B参数规模下,Engram模块显著提升了模型在知识密集型任务以及通用推理和代码数学领域的表现,甚至让模型的早期层能够更高效地处理复杂推理任务。此外,Engram模块还通过软硬结合的工程优化,实现了将百亿参数表卸载至CPU内存,且推理延迟几乎不受影响。DeepSeek团队认为,条件记忆将成为下一代稀疏模型的核心建模原语,其下一代稀疏模型预计将在春节前发布。(IT之家,经AI提炼)

5. 国家数据局:2026 年我国将在智能体、具身智能等前沿方向布局一批数据标准
1 月 6 日消息,2026 年,我国将推出 30 余项数据领域国家标准,新兴领域的标准研制速度持续加快。
2026 年,我国将在智能体、具身智能等前沿方向布局一批数据标准。与此同时,公共数据、高质量数据集、数据基础设施等方向的一批急需标准也将加快出台。此外,城市全域数字化转型、全国一体化算力网等方向的一批重点标准研制工作也将加速研制。在数据识别目录方面,我国将加快建立工业、电信、种业、航天、地理信息、民航等重要领域的数据识别目录。
全国数据标准化技术委员会相关负责人称,我国凭借海量的数据资源和巨大的市场应用规模,在数据标准的研制进程和应用深度上均处于全球第一梯队。2025 年,我国研制了 48 项数据领域国家标准和技术文件,其中超过三分之一的标准在制定过程中就同步开展了验证试点。(央视新闻)
图片、内容来自网络,部分内容经AI整合,侵删